
Abstract
Despite recent advancements in the Large Reconstruction Model (LRM) demonstrating impressive results, when extending its input from single image to multiple images, it exhibits inefficiencies, subpar geometric and texture quality, as well as slower convergence speed than expected. It is attributed to that, LRM formulates 3D reconstruction as a naive images-to-3D translation problem, ignoring the strong 3D coherence among the input images. In this paper, we propose a Multi-view Large Reconstruction Model (M-LRM) designed to reconstruct high-quality 3D shapes from multi-views in a 3D-aware manner. Specifically, we introduce a multi-view consistent cross-attention scheme to enable M-LRM to accurately query information from the input images. Moreover, we employ the 3D priors of the input multi-view images to initialize the triplane tokens. Compared to previous methods, the proposed M-LRM can generate 3D shapes of high fidelity. Experimental studies demonstrate that our model achieves a significant performance gain and faster training convergence.
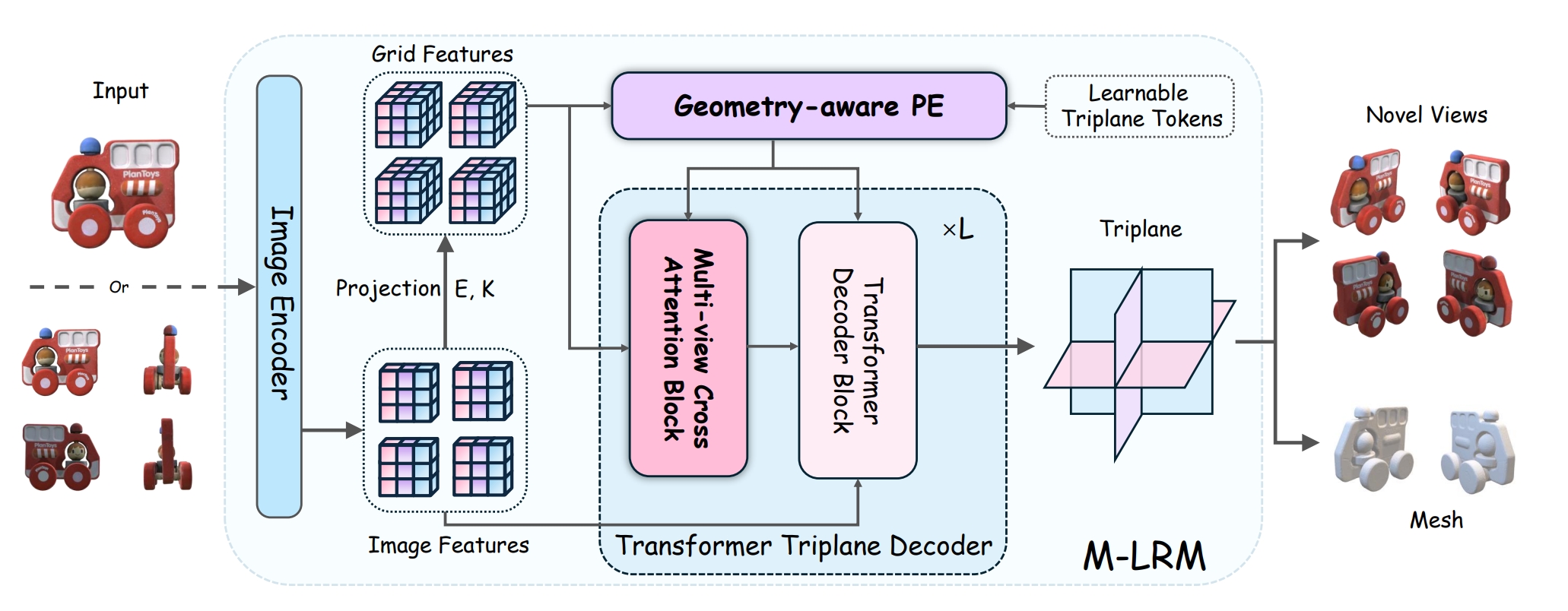
Pipeline. Overview of M-LRM. M-LRM is a fully differentiable transformer-based framework, featuring a feature encoder, geometry-aware position encoding and a multi-view cross attention block. Given multi-view images with corresponding camera poses, M-LRM incorporates the 2D and 3D features to efficiently conduct 3D-aware multi-view attention. The proposed geometry-aware position encoding allows more detailed and realistic 3D generation..